Large Language Models
In a world filled with data, language is your key to making sense of it all. It turns complex information into simple insights, answers questions in a snap, and helps you understand the emotions behind words.
Bluemist AI integrates seamlessly with Hugging Face Transformers, empowering users to accomplish various natural language processing tasks effortlessly. With this integration, you can perform document question answering, generate insightful responses to questions, summarize lengthy text for easier understanding, and analyze sentiment within text. The wrapper simplifies the utilization of powerful models, enhancing productivity and enabling effective interpretation of textual data.
- class TaskModels[source]
Bases:
objectClass representing a collection of tasks and their associated models. It serves as a powerful wrapper for Hugging Face models, streamlining natural language processing tasks.
- It offers simplified interfaces for four key functions:
Document Question Answering
Question Answering
Summarize
Sentiment Analysis
Users can initialize an instance of the class to access these functionalities effortlessly. Bluemist AI is designed to simplify complex NLP operations, making it an invaluable tool for text analysis and understanding.
- get_all_tasks()[source]
Retrieves all available tasks.
- Returns:
A list of all available tasks.
- Return type:
list
- static get_models_for_task(task_name, limit)[source]
Retrieves the available models for a given task.
- Parameters:
task_name (str) – The task for which to retrieve the models.
limit (int, optional) – The maximum number of models to retrieve
- Returns:
A list of available models for the specified task.
- Return type:
list
- perform_task(task_name, input_data, question=None, min_length=30, max_length=130, do_sample=False, override_models=None, limit=5, evaluate_models=True)[source]
Performs the task on the given dataset, evaluate the models and returns comparison metrics
- task_namestr, default=None
Supported tasks can be retrieved from the TaskModels class using the get_all_tasks method.
- input_datastr
Text or information used by the model to perform specific NLP tasks.
- questionstr, default=None
Specific query or question provided as input to the model for question-answering tasks. The model uses this question to find the relevant answer within the provided context.
- min_length: number, default=30
The minimum length of the generated summary. Defaults to 30. The summarization model ensures that the summary is at least this length.
- max_lengthnumber, default=130
The maximum length of the generated summary. Defaults to 130. The summarization model limits the summary to a maximum of this length.
- do_sampleboolean, default=False
Whether to use sampling during summary generation. Defaults to False. When True, the model uses a sampling technique for token selection.
- override_modelsstr or list, default=None
Provide additional models not part of the pre-configured list
- limitint, default=5
Limit the number of models to be compared. Default is 5.
- evaluate_modelsboolean, default=True
Determine if model comparison is requested.
Falsewill override limit as 1
Document Question Answering
Document Question Answering (DQA), also known as Document Visual Question Answering, involves leveraging multi-modal features to answer questions about document images in natural language. It combines text, word positions, and images to generate meaningful responses. An illustrative example showcases DQA balancing cost efficiency with quality customer service in response to specific queries. DQA models prove versatile, adaptable to visually-rich and non-visually-rich documents, aiding in structured document parsing and invoice information extraction.
For more details, refer https://huggingface.co/tasks/document-question-answering
Question Answering
Question Answering (QA) models provide answers to questions based on a given text, aiding in document search and automating responses to frequently asked questions. These models can generate answers either with or without context. QA models can be utilized with the HuggingFace Transformers library using the question-answering pipeline, and various task variants can be addressed.
For more details, refer https://huggingface.co/tasks/question-answering
Summarization
Summarization models are designed to create concise versions of given documents while preserving crucial information. The process involves extracting or generating shorter text while maintaining the essence of the original content. Users can benefit from this tool in various scenarios, such as summarizing research papers for efficient literature review, or condensing lengthy paragraphs for improved understanding. The integration with Hugging Face Transformers allows for effortless implementation and utilization of state-of-the-art summarization models. With a simple API call, users can summarize any given text using pre-trained models, making content processing and comprehension more efficient.
For more details, refer https://huggingface.co/tasks/summarization
Sentiment Analysis
Sentiment Analysis models facilitates the understanding of sentiments conveyed within a given piece of text. It classifies the sentiment as positive, negative, or neutral, enabling valuable insights into the emotional tone of textual content. Users can apply this tool across a range of applications, from social media monitoring to product reviews analysis, helping businesses gauge public opinion and make informed decisions. The integration seamlessly connects users to state-of-the-art sentiment analysis models, simplifying the process and providing accurate sentiment assessments with ease.
For more details, refer https://huggingface.co/blog/sentiment-analysis-python
Code Samples and API deployment
Jupyter notebook with code samples for document-question-answering, question-answering, summarization and sentiment-analysis
pip install -U bluemist[complete]
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
import warnings
warnings.filterwarnings('ignore')
import pytesseract
print("Pytesseract version:", pytesseract.get_tesseract_version())
Pytesseract version: 5.2.0
from bluemist.environment import initialize
from bluemist.llm.task_models import TaskModels
task_models = TaskModels()
print(task_models.get_all_tasks())
TESSDATA_PREFIX: /home/shashank-agrawal/anaconda3/envs/bluemist-test-1/share/tessdata/ TESSDATA_PREFIX: /home/shashank-agrawal/anaconda3/envs/bluemist-test-1/share/tessdata/ ['document-question-answering', 'question-answering', 'summarization', 'sentiment-analysis']
from bluemist.llm.wrapper import perform_task
initialize()
██████╗ ██╗ ██╗ ██╗███████╗███╗ ███╗██╗███████╗████████╗ █████╗ ██╗
██╔══██╗██║ ██║ ██║██╔════╝████╗ ████║██║██╔════╝╚══██╔══╝ ██╔══██╗██║
██████╔╝██║ ██║ ██║█████╗ ██╔████╔██║██║███████╗ ██║ ███████║██║
██╔══██╗██║ ██║ ██║██╔══╝ ██║╚██╔╝██║██║╚════██║ ██║ ██╔══██║██║
██████╔╝███████╗╚██████╔╝███████╗██║ ╚═╝ ██║██║███████║ ██║ ██║ ██║██║
(version 0.1.3 - WordCraft)
Bluemist path :: /home/shashank-agrawal/anaconda3/envs/bluemist-test-1/lib/python3.9/site-packages/bluemist
System platform :: posix, Linux, 6.2.0-35-generic, linux-x86_64, ('64bit', 'ELF')
## Task - Document Question Answering ##
task = "document-question-answering"
image = "https://templates.invoicehome.com/invoice-template-us-neat-750px.png"
question = "What is the invoice number?"
df_document_question_answering = perform_task(task, input_data=image, question=question, limit=1)
df_document_question_answering
Model :: impira/layoutlm-document-qa
| model | score | answer | start | end | |
|---|---|---|---|---|---|
| 0 | impira/layoutlm-document-qa | 0.340383 | us-001 | 16 | 16 |
## Task - Question Answering ##
task = "question-answering"
input = """The Industrial Revolution, which began in the late 18th century, had a
profound impact on society, transforming the way people lived and worked. One of
the most significant changes brought about by the Industrial Revolution was the
shift from agrarian economies to industrial economies. This transition resulted in
the rapid growth of cities as people flocked to urban areas in search of employment
in factories. The development of new machinery and technologies, such as the steam
engine and the spinning jenny, revolutionized manufacturing and led to increased
productivity. However, the benefits of the Industrial Revolution were not evenly
distributed, and many workers faced harsh working conditions, long hours, and low
wages. The social and economic consequences of this era continue to shape our world
today."""
question = """What were the key technological innovations of the Industrial Revolution,
and how did they impact both the economy and the lives of workers during that time?"""
df_question_answering = perform_task(task, input_data=input, question=question, limit=5)
df_question_answering
Model :: distilbert-base-uncased-distilled-squad Model :: deepset/roberta-base-squad2 Model :: Rakib/roberta-base-on-cuad Model :: deepset/bert-large-uncased-whole-word-masking-squad2 Model :: distilbert-base-cased-distilled-squad
| model | score | start | end | answer | |
|---|---|---|---|---|---|
| 0 | distilbert-base-uncased-distilled-squad | 0.556159 | 480 | 515 | steam engine and the spinning jenny |
| 1 | deepset/roberta-base-squad2 | 0.542350 | 480 | 515 | steam engine and the spinning jenny |
| 2 | Rakib/roberta-base-on-cuad | 0.004189 | 0 | 25 | The Industrial Revolution |
| 3 | deepset/bert-large-uncased-whole-word-masking-... | 0.322402 | 480 | 515 | steam engine and the spinning jenny |
| 4 | distilbert-base-cased-distilled-squad | 0.481429 | 476 | 515 | the steam engine and the spinning jenny |
## Task - Summarization ##
task = "summarization"
input = """The Industrial Revolution, which began in the late 18th century, had a
profound impact on society, transforming the way people lived and worked. One of
the most significant changes brought about by the Industrial Revolution was the
shift from agrarian economies to industrial economies. This transition resulted in
the rapid growth of cities as people flocked to urban areas in search of employment
in factories. The development of new machinery and technologies, such as the steam
engine and the spinning jenny, revolutionized manufacturing and led to increased
productivity. However, the benefits of the Industrial Revolution were not evenly
distributed, and many workers faced harsh working conditions, long hours, and low
wages. The social and economic consequences of this era continue to shape our world
today."""
df_summarization = perform_task(task, input_data=input, limit=2)
from pandas import option_context
with option_context('display.max_colwidth', None):
display(df_summarization.style.set_properties(**{'text-align': 'left'}))
Model :: t5-small Model :: t5-base
| model | summary_text | |
|---|---|---|
| 0 | t5-small | the Industrial Revolution began in the late 18th century . it transformed the way people lived and worked . many workers faced harsh working conditions, long hours, and low wages . |
| 1 | t5-base | the Industrial Revolution began in the late 18th century and had a profound impact on society . the shift from agrarian economies to industrial economies led to rapid growth of cities . many workers faced harsh working conditions, long hours, and low wages . |
## Task - Sentiment Anaysis ##
task = "sentiment-analysis"
input = """The new restaurant in town has been creating quite a buzz among food
enthusiasts. The elegant decor, friendly staff, and a diverse menu with a wide
range of culinary delights have been receiving rave reviews. Diners have been
praising the exquisite flavors and presentation of the dishes. However, there
have also been a few complaints about the wait times during peak hours.
Overall, it seems that most customers are delighted with their dining experience
and are looking forward to returning for more delicious meals."""
df_sentiment_analysis = perform_task(task, input_data=input, limit=2)
df_sentiment_analysis
Model :: lxyuan/distilbert-base-multilingual-cased-sentiments-student Model :: ProsusAI/finbert
| model | label | score | |
|---|---|---|---|
| 0 | lxyuan/distilbert-base-multilingual-cased-sent... | positive | 0.534604 |
| 1 | ProsusAI/finbert | positive | 0.858109 |
## Deploy as API ##
from bluemist.llm import api_wrapper
api_wrapper.start_api_server()
INFO: Started server process [19524] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit)
To test the API, open the browser and navigate to http://localhost:8000/docs
API handbook for Document Question Answering

API handbook for Question Answering

API handbook for Sentiment Analysis
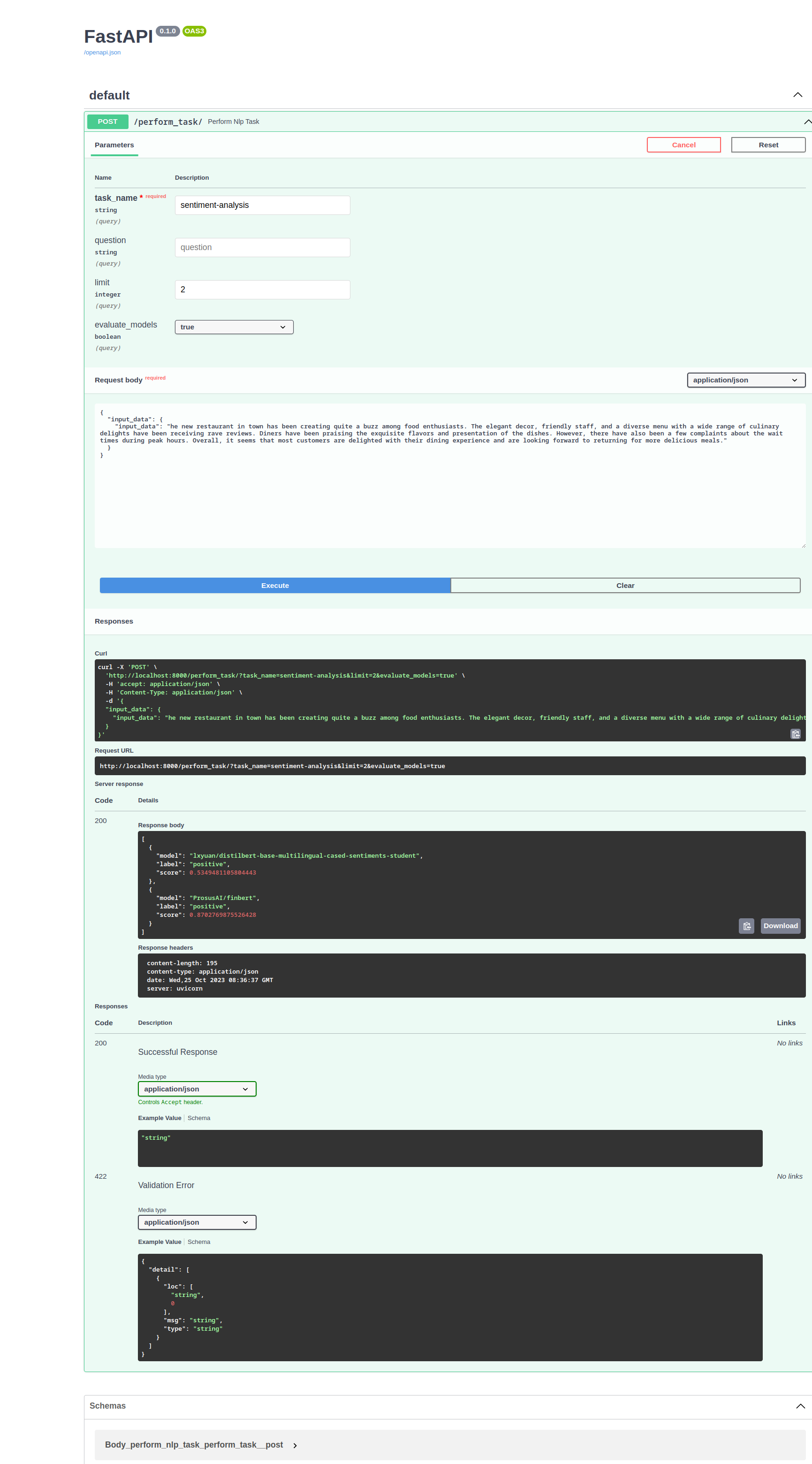
API handbook for Summarization
